개요.
실무에 카프카 컨슈머 애플리케이션을 구축해서 적용시키고 확인해보고 싶고, 한번 정리하는게 좋겠다는 생각이 들었다. 그래서 프로젝트를 하나 팠고, 이것저것 작성하기 위함이다.
글을 쓰기에 앞서 카프카란?
해당 실습한 내용의 관련소스는 여기
이 글에서 얻고자 하는 주제
- 카프카 컨슈머 설정 방법에 따른 컨슘 성능 확인 (?)
- 카프카 컨슈머에서 발생할법한 에러파악 (?)
- 그 외 주키퍼, 카프카 설치 및 프로듀서와 컨슈머 애플리케이션 작성
설치
해당 유튜브 링크보고 그대로 따라했다. 도커 컴포즈 파일 작성하였다. 도커 컴포즈를 사용하면 컨테이너 실행에 필요한 옵션을 docker-compose.yml이라는 파일에 적어둘 수 있고, 컨테이너 간 실행 순서나 의존성도 관리할 수 있다.
docker-compose.yml 파일은 나스내 도커 명령어를 통해 실행하였고 카프카 서버 컨테이너를 띄었다. 그 후 카프카 서버에 접속해서 토픽(Container-topic)을 하나 생성하였다.

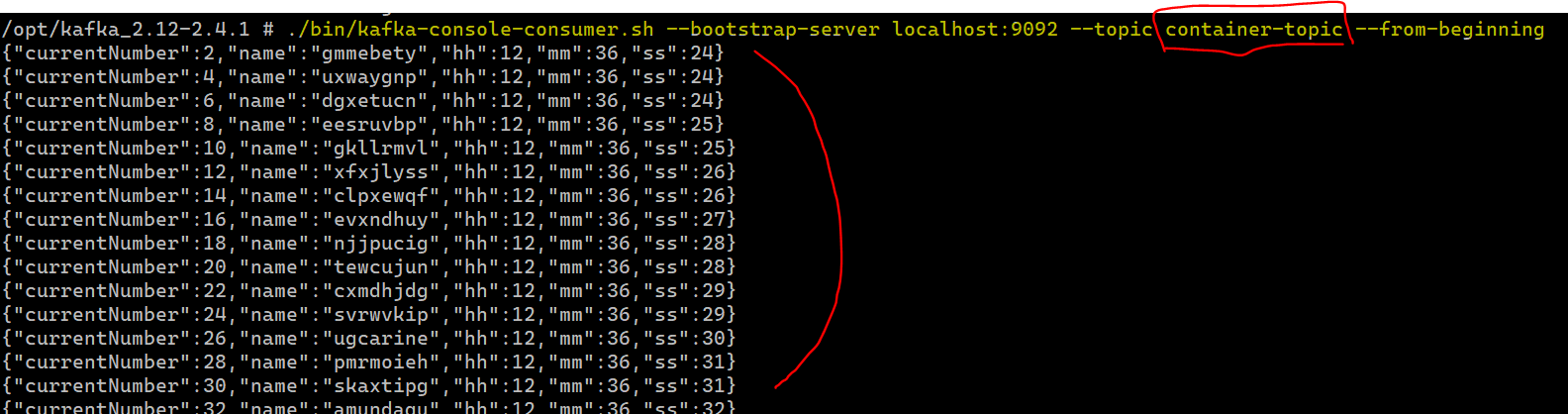
이후 해당 카프카 컨테이너에 접속해서 아래의 명령어를 수행한다.
# [kafka container 접속 이후 토픽 생성]
# $ docker exec -it {container-name} /bin/sh
# $ ./bin/kafka-topics.sh --create --zookeeper zookeeper:2181 --replication-factor 1 --partitions 2 --topic {topic-name}
카프카 프로듀서 구현 (Producer)
Kafka-basis 라는 프로젝트 하위에 서브모듈로 kafka-producer 모듈을 두었다. 그래들 멀티모듈로 구성했고, Container 객체를 토픽 내 메시지로 쏴주는 역할을 수행한다.
카프카 컨슈머 구현 (Consumer)
Kafka-basis 라는 프로젝트 하위에 서브모듈로 kafka-consumer 모듈을 두었다. 그래들 멀티모듈로 구성했고, 토픽 내 메시지로 있는 Container 객체를 Json Deserializer 하여 컨슘한다.
프로듀서와 컨슈머가 통신 포맷 (Container 객체 설정)
Kafka-basis 프로젝트 하위에 서브모듈로 kafka-common 모듈을 두고, 해당 모듈 하위에 Container 라는 객체를 두어 프로듀서와 컨슈머가 통신하는 메세지 포맷을 설정하였다.
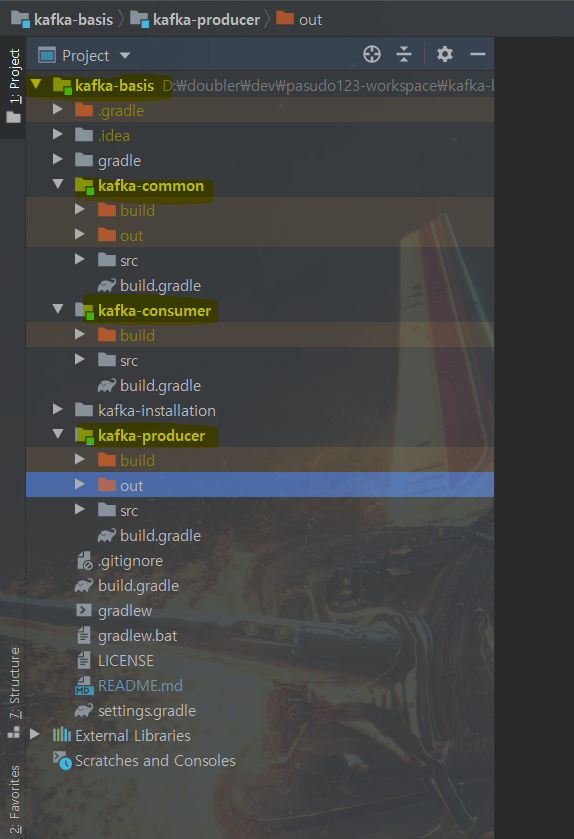
프로젝트 구성도
Spring for Apache Kafka Consumer Configuration Java code
@Configuration
@EnableKafka
@RequiredArgsConstructor
public class CustomConsumerConfig {
private final CustomKafkaProperties customKafkaProperties;
@Bean
public ConsumerFactory<String, Container> consumerFactory() {
final Map<String, Object> configProps = new HashMap<>();
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, customKafkaProperties.getBootstrapServers());
configProps.put(ConsumerConfig.GROUP_ID_CONFIG, customKafkaProperties.getGroupId());
configProps.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, customKafkaProperties.getOffset());
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
// JsonDeserializer 를 Container 객체에 대해서 수행하고 있음을 명시.
return new DefaultKafkaConsumerFactory<>(configProps, new StringDeserializer(), new JsonDeserializer<>(Container.class));
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, Container> kafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory<String, Container> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}ConsumerFactory 를 통한 컨슈머 설정
- ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG
- 카프카 클러스터에 처음 연결을 하기 위한 호스트와 포트정보의 목록이다. 나는 로컬환경이기 때문에 localhost:9092 로 설정되어 있다.
- ConsumerConfig.GROUP_ID_CONFIG
- 컨슈머가 속한 컨슈머 그룹을 식별할 수 있는 ID 를 부여한다. 그룹 아이디끼리 컨슈머 그룹을 분리시킬 수 있다.
- ConsumerConfig.AUTO_OFFSETT_RESET_CONFIG
- 카프카에서 초기 오프셋이 없거나 오프셋이 더이상 존재하지 않는 경우 다른 옵션으로 리셋하기 위한 설정이 다. 오프셋 설정에는 none, earliest(가장 오래된 offset), latest(가장 최신 offset) 가 있고 나는 latest 로 설정하였다. 여기서 오프셋이란 컨슈머에게 전송될 파티션 내의 위치 값이다.
- ConsumerConfig.{KEY/VALUE}_DESERIALIZER_CLASS_CONFIG
- 아파치 카프카는 레코드 Key, Value 값을 직렬화 및 역직렬화 하기위한 API 를 제공한다. 스프링에서 프로듀서/컨슈머에 대한 설정이 추상화가 되어있어서 serializer 또는 deserializer 하기 위한 클래스를 지정할 수 있다.
- 스프링 아파치 카프카 또한 Jackson JSON 객체 매퍼를 기반으로 하는 JsonSerializer 와 JsonDeserializer 클래스를 제공하고 있다. JsonSerializer 이용시 Java Object 를 byte[] 로 작성가능하고 JsonDeserializer 역시 byte[] 를 Java Object 로 역직렬화 가능하다. 따라서 Deserializer 시 적절한 Class<T> targetType 이 필요하다.
나는 위의 코드에서 Container.class 라는 객체를 토픽 내 메시지로서 역직렬화 할 수 있도록 설정해두었다.
ConcurrentKafkaListenerContainerFactory<String, Container>
@KafkaListener 애노테이션이 있는 메소드의 컨테이너를 만드는데 사용한다. ConcurrentKafkaListenerContainer 를 사용하는 경우에 모든 컨슈머 스레드는 단일 리스너 인스턴스를 호출한다. 그리고 하나 이상의 KafkaMessageListenerContainer 를 사용하기 위해, 즉 멀티 스레드 컨슘을 위해서 ConcurrentKafkaListenerContainer 를 사용할 수 있다. ConcurrectKafkaListenerContainer 의 setConcurrency() 를 통해 KafkaMessageListenerContatainer 를 늘릴 수 있다.
만약 setConcurrency(3) 은 3개의 KafkaMessageListenerContainer 인스턴스를 만든다. 이는 결국 메시지 리스너를, 스레드를 늘리는 것이다.
여기 부분에서 ConsumerApplication 을 (1)한 대의 Machine 에서 여러개의 Thread 로 메세지 리스너를 동작시키는 방법이 하나 있고, (2)여러 대의 Machine 에서 각각 하나의 Thread 를 메세지 리스너로 동작시키는 방법도 생각해볼 수 있다. (1) 의 방법으로 scale up 이고, (2) 의 방법은 scale out 이다. (관련링크 참고)
KafkaMessageListenerContainer
싱글스레드 메시지 리스너이다. 자동으로 파티션 할당 및 자동사용자 구성을 지원한다.
Spring for Apache Kafka Consumer Listner Java code
@Service
@Slf4j
public class ContainerReceiver {
@KafkaListener(topics = "${kafka.consumer.topic}")
public void listen(@Payload Container container) {
log.info("==> Container[{}] : {} ({}:{}:{})",
container.getCurrentNumber(),
container.getName(),
container.getHh(),
container.getMm(),
container.getSs());
}
}
group id 조회 (토픽 내 메시지만 쏴주고 있는 상태)

group id 조회 (컨슈머 애플리케이션 동작하고 있는 상태)

컨슈머 애플리케이션 로그 확인 (setConccurency 미설정)

컨슈머 애플리케이션 로그 확인 (setConccurency(2) 설정)

group id 재조회 (컨슈머 애플리케이션 동작하고 있는 상태)

위의 group-id 재 조회시 파티션에 쌓인 Lag 가 균등하게 쌓임을 확인해 볼 수 있다.
+) Lag 란? (유튜브 링크 : 데브원영님이 한글로 올리심)
컨슈머가 읽은 마지막 오프셋과 프로듀서가 넣은 마지막 오프셋의 차이
Lag 가 높다는 것은 아래의 내용을 유추해볼 수 있다.
- 컨슈머 애플리케이션이 카프카 서버에서 제외되었다.
- 컨슈머의 처리속도가 프로듀서가 토픽에 메시지를 넣는 속도를 못따라가기 때문에.
BatchListeners & max.poll.records
토픽 내의 메시지를 배치형태로 들고오기 위해선 consumerFactory() 에서 setBatchListener(true) 라고 설정해준다. 그리고 이후에 @KafkaListener 에 containerFactory bean 이름을 설정해 커스텀하게 KafkaListenerContainerFactory 를 설정해줄 수 있다. max.poll.records 만큼의 레코드 수를 한번에 poll() 한다. 기본값은 500이다.
// 컨슈머 측에서 poll() 단일호출하여 들고 올 수 있는 최대레코드 수 (디폴트 : 500)
/** max.poll.records 값을 50으로 설정해두었다. **/
configProps.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, customKafkaProperties.getMaxPollRecords());
return new DefaultKafkaConsumerFactory<>(configProps, new StringDeserializer(), new JsonDeserializer<>(Employee.class));@Bean
public ConcurrentKafkaListenerContainerFactory<String, Employee> employeeContainerFactory(){
ConcurrentKafkaListenerContainerFactory<String, Employee> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(employeeConsumerFactory());
factory.setBatchListener(true);
return factory;
}@KafkaListener(
topics = "${kafka.consumer.employee-topic}",
containerFactory = "employeeContainerFactory"
)
public void listen(@Payload List<Employee> employees) {
employees.forEach(employee -> {
log.info("==> Employee[{}] : {} ({}:{}:{})",
employee.getCurrentNumber(),
employee.getName(),
employee.getHh(),
employee.getMm(),
employee.getSs());
});
log.info("====> Employees Size : [{}]", employees.size());
}
- Container 는 poll() 할때마다 하나씩 들고오는 상태이지만, Employee 는 poll() 할때마다 25개씩 들고오고 있다. 만약에 Employee 메시지가 25개 이상 쌓여있다면 25개씩 들고오지만 이후에 그 개수 이하로 떨어지는 경우에는 떨어진 개수만큼만 들고온다.
Error1.
failed: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
Error2.
Caused by: java.lang.IllegalArgumentException: The class 'package 위치 및 객체명' is not in the trusted packages: [package-위치 및 객체명]. If you believe this class is safe to deserialize, please provide its name. If the serialization is only done by a trusted source, you can also enable trust all (*).
관련 포스트
- 컨슈머 옵션 일부 살펴보기
- 에러관련 & 리밸런싱
- kafka gracefully shutdown
- Exactly-Once-Delievery
관련링크
'Spring' 카테고리의 다른 글
| 20200801 [springboot] gradle-multi-module 시, 신경써야할 것 정리. (0) | 2020.08.07 |
|---|---|
| 20200523 [jpa] 스프링부트 실행 시, 디비 데이터 삽입 및 테스트 코드 상에서 데이터 삽입. (수정 : 2021-08-22) (0) | 2020.07.01 |
| 20200328 [redis & springboot] 레디스를 이용한 세션 클러스터링. (수정 : 2020-09-24) (0) | 2020.03.28 |
| 20180304 @RequestMapping 에 대한 이해. (수정 2020-08-17) (2) | 2020.03.25 |
| 20191006 Request Payload & Form Data (SpringBoot & Vue) (0) | 2019.10.06 |

