20210829 [error] org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags
ErrorMarking 2021. 8. 29. 14:45개요
jpa 이용할 시에 @OneToMany 를 여러개 페치조인으로 들고올 때, 발생되는 멀티백페치 익셉션 에러 탐구
원인
hibernate 에서는 @OneToMany 로 컬렉션에 대한 페치조인을 들고올 때, hibernate 는 java/kotlin 의 List Collection 을 unordered List 로 간주하고 BagType 으로 인식한다. hibernate 는 1개의 BagType 에 대한 fetchJoin 은 허용하지만 여러 개의 BagType 에 대한 fetchJoin 은 허용하지 않는다. 발생되는 코드영역을 보면 아래와 같다.
protected void postInstantiate() {
// 생략
CollectionPersister[] collectionPersisters = getCollectionPersisters();
List bagRoles = null;
if ( collectionPersisters != null ) {
// 생략
for ( int i = 0; i < collectionPersisters.length; i++ ) {
// BagType 이면 해당 BagRoles 에 해당 타입을 추가한다.
if ( isBag( collectionPersisters[i] ) ) {
if ( bagRoles == null ) {
bagRoles = new ArrayList();
}
bagRoles.add( collectionPersisters[i].getRole() );
}
);
}
}
else {
collectionDescriptors = null;
}
// bagRoles 의 개수가 몇개인지 판단해서 에러를 발생시킨다.
if ( bagRoles != null && bagRoles.size() > 1 ) {
throw new MultipleBagFetchException( bagRoles );
}
}
private boolean isBag(CollectionPersister collectionPersister) {
return collectionPersister.getCollectionType().getClass().isAssignableFrom( BagType.class );
}위의 코드의 collectionPersisters 내 collectionType 가지고 디버깅하면, 아래 사진처럼 actors 와 songs 두 컬렉션 모두 org.hibernate.type.BagType 으로 잡혀져 있는 것이 보인다.


이제 문제를 일으킨 나의 코드를 보자.
영화 엔티티
영화는 여러 명의 배우와 여러 곡의 노래가 존재한다.
영화를 단 건 조회할 시에 배우와 노래를 한꺼번에 fetchJoin 으로 들고오는 로직을 작성했다.
@Entity
@Table(name = "movie")
class Movie(
@Column(name = "title", columnDefinition = "VARCHAR(50) not null")
val title: String
) : BaseEntity() {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
var id: Long? = null
protected set
@OneToMany(targetEntity = Actor::class, mappedBy = "movie", fetch = FetchType.LAZY, cascade = [CascadeType.ALL])
var actors: MutableList<Actor> = mutableListOf()
@OneToMany(targetEntity = Song::class, mappedBy = "movie", fetch = FetchType.LAZY, cascade = [CascadeType.ALL])
var songs: MutableList<Song> = mutableListOf()
fun addActor(actor: Actor) {
val actorIds = actors.map { currentActor -> currentActor.id }
if (actorIds.contains(actor.id).not()) {
actors.add(actor)
actor.settingMovie(this)
}
}
fun addSong(song: Song) {
val songIds = songs.map { currentSong -> currentSong.id }
if (songIds.contains(song.id).not()) {
songs.add(song)
song.settingMovie(this)
}
}
}
영화 엔티티를 조회하는 querydsl 코드
fetchJoin 으로 songs 와 actors 를 같이 들고온다.
@Repository
@Transactional(readOnly = true)
class MovieCustomRepository: QuerydslRepositorySupport(Movie::class.java) {
fun findOneWithSongsAndActorsById(id: Long): Optional<Movie> {
return Optional.ofNullable(
from(movie)
.leftJoin(movie.songs, song).fetchJoin()
.leftJoin(movie.actors, actor).fetchJoin()
.where(
movie.id.eq(id)
)
.distinct()
.fetchOne()
)
}
}
해결방식1 : @OrderColumn 을 붙이기
자바 콜렉션의 List 는 정렬되지 않은 상태로써, Hibernate 에서는 이를 BagType 으로 처리하는데, Hibernate 에서 ListType 으로 처리하도록 해주어야 한다. 별도의 annotation @OrderColumn 을 추가해준다. (@OrderBy 가 아닌 @OrderColumn 이다. 둘은 같이 사용하지 못하고, 일부 차이라면 @OrderColumn 은 안에 정렬 기준 값이 정수여야 한다.)
https://docs.oracle.com/javaee/6/api/javax/persistence/OrderColumn.html
https://docs.oracle.com/javaee/7/api/javax/persistence/OrderBy.html
아래와 같이 작성하면 actors 와 songs 는 코틀린 콜렉션상 list 이고, hibernate 에서 인식할 시에 정렬된 리스트로 ListType 으로 처리한다.
@OneToMany(targetEntity = Actor::class, mappedBy = "movie", fetch = FetchType.LAZY, cascade = [CascadeType.ALL])
@OrderColumn(name = "id")
var actors: MutableList<Actor> = mutableListOf()
@OneToMany(targetEntity = Song::class, mappedBy = "movie", fetch = FetchType.LAZY, cascade = [CascadeType.ALL])
@OrderColumn(name = "id")
var songs: MutableList<Song> = mutableListOf()songs 의 collectionType 이 org.hibernate.type.ListType 으로 잡힌것을 볼 수 있다.

해결방식2 : FetchJoin 을 나눠서 들고오기 (추천)
한 방 쿼리로 문제가 될 수 있다면 오히려, 쿼리를 둘로 나누어서 들고오는 것도 하나의 방법이 될 수 있다.
아까 작성했던. OrderColumn(name = "id") 를 지우고 querydsl 코드를 아래로 바꾼다.
fun findOneWithSongs(id: Long): Optional<Movie> {
return Optional.ofNullable(
from(movie)
.leftJoin(movie.songs, song).fetchJoin()
.where(
movie.id.eq(id)
)
.distinct()
.fetchOne()
)
}
fun findOneWithActors(id: Long): Optional<Movie> {
return Optional.ofNullable(
from(movie)
.leftJoin(movie.actors, actor).fetchJoin()
.where(
movie.id.eq(id)
)
.distinct()
.fetchOne()
)
}이렇게 하고 한 트랜잭션 내의 서비스레이어에서 쿼리를 두 번 호출해서 사용하는 방법도 있다. 이렇게 한다면 추가적인 장점으론 한방쿼리가 가지는 처리속도가 긴 문제를 나누어 쿼리를 호출함으로써 개선시킬 여지도 있다. 그리고 연관관계가 movie 뿐만 아니라 다른 엔티티도 복잡하게 얽혀있는 경우에 드라이빙되는 테이블, 즉 주체가 되는 테이블을 기준으로 조회하여 코드의 가독성을 높이는 경우도 생각할 수 있다.
잘못된 해결방식 : List 자료구조를 Set 으로 바꾸는 것
나도 처음 간단한 변경방식으로 actors 나 songs 를 set 형태로 바꾸면 해결될 문제라고 생각했었다. 이 부분에 대해서 잠시 사내에서 코드리뷰를 받았는데 우선은 엔티티가 현재 영속성 처리가 되지 않은 상태에서 set 에 넣으면 동일 필드 데이터 건의 경우 사라질 수 있는 문제를 제기해주었다. 추가적으로 레퍼런스에서도 List 를 Set 으로 바꿔서 해결하는 것은 잘못된 방식이라고 언급하고 있었다. 뭐 때문에 그러는걸까?
문제를 알기 이전에 일단 카다시안 곱이라는 것을 알아야 한다.
관련 내용은 여기 유튜브를 보자. 그림으로 보니깐 한결 수월하다..
https://youtu.be/58i-sZ6h1mI
조인조건이 불명확하지 않은 상태에서 단순 조인으로 조회하면, combination 으로 들고오는 데이터의 수가 확 늘어나는걸로 보인다.
Song 컬렉션 자료구조를 set 으로 변경하고 movie 단 건 조회에 대한 테스트를 실시한다.
// movie & song 연관관계 set 으로 설정
@OneToMany(targetEntity = Song::class, mappedBy = "movie", fetch = FetchType.LAZY, cascade = [CascadeType.ALL])
var songs: MutableSet<Song> = mutableSetOf()
// querydsl
fun findOneWithSongsAndActorsById(id: Long): Optional<Movie> {
return Optional.ofNullable(
from(movie)
.leftJoin(movie.songs, song).fetchJoin()
.leftJoin(movie.actors, actor).fetchJoin()
.where(
movie.id.eq(id)
)
.distinct()
.fetchOne()
)
}
대략적인 내용은 아래와 같이 생각하면 된다..
movie는 5명의 actor가 연관관계가 맺어져있다.
movie는 5곡의 song가 연관관계가 맺어져있다.
이렇게 데이터를 세팅하고 querydsl 로 두 엔티티를 페치조인하면 결과는 actors 가 25개 나온다. 확 늘어났다. !
1 * 5 * 5 가 되어서 조인으로 25개의 actors 가 중복인 형태로 조회가 되었다. actor 를 조회할 때 song 가 같이 페치조인되면서 actors 기준으로 조합이 되는 경우가 다 나왔다고 생각한다. 많으면 많을수록 더 늘어날 것이다..
(movie, actor1, song1), (movie, actor1, song2), (movie, actor1, song3), (movie, actor1, song4), (movie, actor1, song5),
(movie, actor2, song1), (movie, actor2, song2), (movie, actor2, song3), (movie, actor2, song4), (movie, actor2, song5) ...
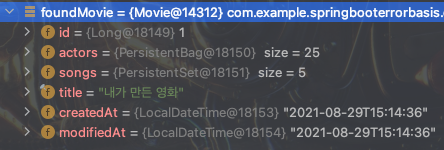
동일한 조건으로 영화를 3개 추가하고, 각각의 영화에 actor(List) 와 song(Set) 이 5개 있는 상태에서 movie 를 전체 다 들고와도 결과는 동일한다.

이번에는 actor 와 song 둘 다 Set 으로 변경해보았다.
@OneToMany(targetEntity = Actor::class, mappedBy = "movie", fetch = FetchType.LAZY, cascade = [CascadeType.ALL])
var actors: MutableSet<Actor> = mutableSetOf()
@OneToMany(targetEntity = Song::class, mappedBy = "movie", fetch = FetchType.LAZY, cascade = [CascadeType.ALL])
var songs: MutableSet<Song> = mutableSetOf()이런 경우에는 오히려 카다시안 곱의 형태가 나타나지 않고 잘 들고오는 걸로 보인다.

그래서 결론
결론은 없다. 기존 코드에 List 가 있는데 Set 을 중간에 끼워서 fetchJoin 으로 여러개 들고올 일이 있는 경우를 만들지 말자.
쿼리를 나누는 방법이 가장 나아보이고, 그 이후에 OrderColumn 을 붙여서 쓰는 방법도 고려해볼만하다. (OrderColumn 을 쓰게되면 hibernate 에서 ListType 으로 잡는다.) 여기에 붙였을 때 사이드 이펙트? multibagFetchException 는 해결될텐데.. 지금 쓰는 시점에는 별도로 생각나지 않는다..

